

服務熱線
86-132-17430013

產(chǎn)品展示PRODUCTS

| 品牌 | 其他品牌 |
|---|
西門子代理商 秦皇島西門子代理商 秦皇島西門子代理商
生物的學習系統(tǒng)隨處可見,從只有300個左右神經(jīng)元的低級蛔蟲(秀麗隱桿線蟲),到有兩千億個神經(jīng)元的成年大象的大腦,比比皆是。無論是在果蠅、蟑螂、黑猩猩或海豚體內(nèi),所有的神經(jīng)元所做的事情都是一樣的:處理并傳遞信息。所有生物做這些事情的原因也是*的:避免危險,使物種地生存并繁衍,所有的生物必須能感知環(huán)境,并做出相應的反應,記住那些是危險信號,哪些是有益的信號。簡言之,無論對單個個體還是整個物種,學習都是其在自然界生存的必要條件。然而,這一鐵的規(guī)律也越來越適用于人造系統(tǒng)。
Volker Tresp博士是西門子機器研究領域內(nèi)的資深權(quán)威人士,也是慕尼黑大學的電腦科學教授。他說,學習有三種:記憶(如,記住事實的能力)、技能(如,學習如何投球的能力)和抽象能力(如,從大量觀察中得出規(guī)律的能力)。電腦是*個領域內(nèi)的高手,但目前正在另外兩個領域內(nèi)迅速地趕超。例如,可以毫厘不差地生產(chǎn)出厚度均勻且平整的鋼板——西門子20多年來一直在這個領域處于*地位。Tresp說,“在這里,較簡單的模式就是先給出預測,然后去檢驗產(chǎn)出品是否符合規(guī)格要。求。如,首先明確對高級鋼板產(chǎn)成品的要求,自動軋鋼廠結(jié)合傳感器提供的數(shù)據(jù)(成分、帶鋼溫度等),在已有信息的基礎上,估算所需的壓力。根據(jù)產(chǎn)出品數(shù)據(jù)相應地進行實時調(diào)整,最終慢慢地算出正確的壓力,并產(chǎn)出符合厚度要求的鋼板。“以神經(jīng)網(wǎng)絡為基礎的學習系統(tǒng)中,” Tresp解釋,“可以通過調(diào)整影響既定參數(shù)(如厚度)的全部因素的權(quán)重矩陣來實現(xiàn)這種調(diào)節(jié)的目標。”
除記憶和改進技能的能力外,人造系統(tǒng)正逐漸被用來進行概括或抽象個體的特點,以此來判斷它是否屬于某一個群體。光學字符識別(OCR)就是一個例子,它以前是用來高速掃描并分揀信件的。該技術(shù)約在1985年初次面世,與那時相比,現(xiàn)在其精確度已經(jīng)有了驚人的提高,識別范圍也已從單個數(shù)字提高到95%以上手寫拉丁字母及90%以上阿拉伯語手寫體。其實,早在2007年,西門子ARTread學習系統(tǒng)就曾經(jīng)榮獲文檔分析與識別國際會議組織的阿拉伯語光學字符識別(OCR)比賽*名。由于光學字符識別技術(shù)的高度可靠性,它已經(jīng)開始被逐漸應用到諸如車牌自動識別和工業(yè)視覺中(如需了解更多信息,請參閱第67頁)。
機器學習能力將會如何發(fā)展呢?顯而易見的是,隨著感應器在能源和數(shù)字方面的大規(guī)模應用,可以很容易地通過本地和信息網(wǎng)絡獲得更多數(shù)據(jù),機器學習發(fā)展的前景十分廣闊。網(wǎng)絡環(huán)境下的學習應用主要體現(xiàn)在兩個大型項目中。*個是Theseus項目,西門子主導MEDICO技術(shù),該項目主要是從圖像和文本中提取語義信息,促成各種新的應用程序來改善醫(yī)生的工作流程。第二個項目是歐盟的大規(guī)模知識加速器項目(LarKC),研發(fā)可伸縮查詢、推理能力和鍵連資料的機器學習方法。“能夠和鍵連資料一起學習,” Tresp說,“這才是今天最令人激動的地方!”
Arthur F. Pease
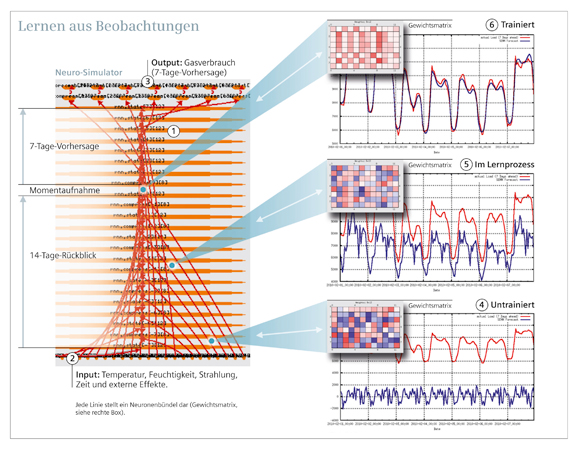
以神經(jīng)系統(tǒng)為基礎的學習體系(1)基于輸入的信息(2)根據(jù)為期14天的培訓對未來7天的氣體需求做出預測(3)。
學習通過對部分學習(5)和*訓練(6)的隨機權(quán)重組合(4)在三個片段中得到反映。
以神經(jīng)網(wǎng)絡為基礎的系統(tǒng)有能力處理大量的輸入數(shù)據(jù),并調(diào)整最終的輸出成果。為實現(xiàn)這一點,這種系統(tǒng)必須建立起一種數(shù)學模型來復制現(xiàn)實世界中相應的實物。這種模型本質(zhì)上是一種決策單元的集合。從整體角度來看,可以通過矩陣形式來反映決策單元。取決于應用程序的復雜程度,可能要求數(shù)百個互動矩陣。
起初,決策單元之間的互動是隨機的。那么,當系統(tǒng)開始進入學習階段,其錯誤率——預期和實際觀察到的結(jié)果之間的差異——很高(4)。和真實的結(jié)果相比較后,錯誤率會被反饋到每個矩陣中(箭頭向右指向每個方框),然后就開始調(diào)整每個決策單元在內(nèi)部的權(quán)重,避免隨機出現(xiàn),并根據(jù)已學到的信息去修正每個輸入?yún)?shù)(箭頭從每個方框指向左側(cè))。
每次這樣的往復都在不斷減少錯誤率,最后,在上千次這樣的信息往復以后,系統(tǒng)就慢慢學會了如何描述完整的輸入信息流,結(jié)果就是*復制(6)——并最終預測——現(xiàn)實世界的行為。
![]()
 微信二維碼
微信二維碼